Python Notes
附代码

Python相关
注:该笔记为备忘和快速查询所创建,尚不完全。
数据结构
单
Str
单个字符
- ‘a'+1='b’
- ord(char) 对应ascll码
- chr(num) 对应字符
chr(ord('a')+1) # 'b'- ‘a'+1='b’
统计词频
import collections
text = "I'm a hand some boy!"
frequency = collections.Counter(text.split())
diction = dict(frequency)
dict
- 按key/value排序
sorted(dict.items(), key=lambda x: x[1], reverse=True) #reverse = True按大到小排序
list
增加元素
- list.append()
li=['a', 'b'] li.append([2,'d']) li.append('e') #输出为:['a', 'b', [2, 'd'], 'e'] li=['a', 'b'] li.append([2,'d']) li.append('e') #输出为:['a', 'b', [2, 'd'], 'e']- list.insert()
li=['a', 'b'] li.insert(0,"c") #输出为:['c', 'a', 'b'] li=['a', 'b'] li.insert(0,"c") #输出为:['c', 'a', 'b']- list.extend()
li=['a','b'] li.extend([2,'e']) #输出为:['a', 'b', 2, 'e'] li=['a','b'] li.extend([2,'e']) #输出为:['a', 'b', 2, 'e']删除元素
- 使用del删除指定位置元素
li = [1, 2, 3, 4] del li[3] # Output [1, 2, 3]- 使用list方法pop删除元素
li = [1, 2, 3, 4] li.pop(2) # Output [1, 2, 4]- 使用切片删除元素
li = [1, 2, 3, 4] li = li[:2] + li[3:] # Output [1, 2, 4]- 使用list方法remove删除指定值的元素
li = [1, 2, 3, 4] li.remove(3) # Output [1, 2, 4]获取元素索引
第一个索引
>>> lst = ['A', 1, 4, 2, 'A', 3] >>> lst.index('A') 0所有索引
>>> def get_index1(lst=None, item=''): ... return [index for (index,value) in enumerate(lst) if value == item] >>> lst = ['A', 1, 4, 2, 'A', 3] >>> get_index1(lst, 'A') [0, 4]
多条件排序
#假设数据如下。
data = '''
区服,玩家id,累积消费
3,a,2380
1,b,11900
4,e,3250
1,k,100
4,j,599
2,m,872
3,f,5560
1,y,2500
'''
items = [x.split(',') for x in filter(None,data.split('\n'))[1:]] #去掉空行和忽略首行并把字符串转成二维数组
#方法一
items.sort(key=lambda x:int(x[2]),reverse=True)#先排消费
items.sort(key=lambda x:int(x[0]))#然后排区服
#import operator
#items.sort(key=operator.itemgetter(0)) #只能根据第一个元素排序
print '\n'.join([','.join(x) for x in items])
print '-----------'
#方法二
items = sorted(items,key=lambda x:(int(x[0]),-int(x[2])))
print '\n'.join([','.join(x) for x in items])
- 返回排序列表的索引
>>> lis = [1,2,3,0,1,9,8]
>>> sorted(range(len(lis)), key=lambda k: lis[k])
[3, 0, 4, 1, 2, 6, 5]
相互转换
str-list
- str »> list
str1 = "12345"
list1 = list(str1)
print list1
#输出:['1', '2', '3', '4', '5']
str2 = "123 sjhid dhi"
list2 = str2.split() #or list2 = str2.split(" ")
print list2
#输出:['123', 'sjhid', 'dhi']
str3 = "www.google.com"
list3 = str3.split(".")
print list3
#输出:['www', 'google', 'com']
- list »> str
str4 = "".join(list3)
print str4 #输出:wwwgooglecom
str5 = ".".join(list3)
print str5 #输出:www.google.com
str6 = " ".join(list3)
print str6 #输出:www google com
按指定符分隔读取/写出
txt文件
#读取
f = open("./image/abc.txt","r")
lines = f.readlines() #结尾会包含\n
lines_2 = f.read().splitlines() #结尾不含\n
#'\t'为分隔符
lines = [i[:-1].split() for i in lines]
#写出
f_out = open("./sample.txt",'w')
for line in lines:
f_out.write(line)
f_out.write('\n')
f_out.close()
OJ 输入输出
import sys
for line in sys.stdin:
a = line.split()
print(int(a[0]) + int(a[1]))
Numpy
初始化数组
#1、创建一个长度为10的数组,数组的值都是0
np.zeros(10,dtype=int)
#2、创建一个3x5的浮点型数组,数组的值都是1
np.ones((3,5),dtype=float)
#3、创建一个3x5的浮点型数组,数组的值都是3.14
np.full((3,5),3.14)
#4、创建一个3x5的浮点型数组,数组的值是一个线性序列,从o开始,到20结束,步长为2,(它和内置的range()函数类似
np.arange(0,20, 2)
#5、创建一个5个元素的数组,这5个数均匀的分配到0~1
np.linespace(0, 1, 5)
#6、创建一个3x3的,在0~1均匀分配的随机数组成的数组
np.random.random(3,3)
#7、创建一个3x3的,均值为0,方差为1,正太分布的随即数数组
np.random.normal(0,1,(3,3))
#8、创建一个3x3的,[0,10]区间的随机整形数组
np.random.randint(0,10,(3,3))
#9、创建一个3x3的单位矩阵
np.eye(3)
#10、创建一个由3个整形数组组成的未初始化的数组,数组的值是内存空间中的任意值
np.empty(3)
np.random.choice()
import numpy as np
# 参数意思分别 是从a 中以概率P,随机选择3个, p没有指定的时候相当于是一致的分布
a1 = np.random.choice(a=5, size=3, replace=False, p=None)
print(a1)
# 非一致的分布,会以多少的概率提出来
a2 = np.random.choice(a=5, size=3, replace=False, p=[0.2, 0.1, 0.3, 0.4, 0.0])
print(a2)
# replacement 代表的意思是抽样之后还放不放回去,如果是False的话,那么出来的三个数都不一样,如果是True的话, 有可能会出现重复的,因为前面的抽的放回去了。
a : 1-D array-like or int
If an ndarray, a random sample is generated from its elements.
If an int, the random sample is generated as if a was np.arange(n)
np.flatnonzero()
>>> x = np.arange(-2, 3)
>>> x
# array([-2, -1, 0, 1, 2])
>>> np.flatnonzero(x)
# array([0, 1, 3, 4])
import numpy as np
d = np.array([1,2,3,4,4,3,5,3,6])
haa = np.flatnonzero(d == 3)
print (haa)
[2 5 7]
np.argsort()
One dimensional array:一维数组
>>> x = np.array([3, 1, 2])
>>> np.argsort(x)
# array([1, 2, 0])
Two-dimensional array:二维数组
>>> x = np.array([[0, 3], [2, 2]])
>>> x
#array([[0, 3],[2, 2]])
>>> np.argsort(x, axis=0) #按列排序
#array([[0, 1],[1, 0]])
>>> np.argsort(x, axis=1) #按行排序
#array([[0, 1],[0, 1]])
>>> x = np.array([3, 1, 2])
>>> np.argsort(x) #按升序排列
array([1, 2, 0])
>>> np.argsort(-x) #按降序排列
array([0, 2, 1])
np.arange() & np.reshape()&np.split()
import numpy as np
# Test 1
A = np.arange(12).reshape(3, 4)
#[[ 0 1 2 3]
#[ 4 5 6 7]
#[ 8 9 10 11]]
# 纵向分割, 分成两部分, 按列分割
print np.split(A, 2, axis = 1)
# 横向分割, 分成三部分, 按行分割
print np.split(A, 3, axis = 0)
#[array([[0, 1],
# [4, 5],
# [8, 9]]), array([[ 2, 3],
# [ 6, 7],
# [10, 11]])]
#[array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])]
# Test 2
# 不均等分割
print np.array_split(A, 3, axis = 1)
# Test 2 result
[array([[0, 1],
[4, 5],
[8, 9]]), array([[ 2],
[ 6],
[10]]), array([[ 3],
[ 7],
[11]])]
# Test 3
# 垂直方向分割
print np.vsplit(A, 3)
# 水平方向分割
print np.hsplit(A, 2)
# Test 3 result
[array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])]
[array([[0, 1],
[4, 5],
[8, 9]]), array([[ 2, 3],
[ 6, 7],
[10, 11]])]
np.concatenate()
>>> a = np.array([[1, 2], [3, 4]])
>>> b = np.array([[5, 6]])
>>> np.concatenate((a, b), axis=0)
array([[1, 2],
[3, 4],
[5, 6]])
>>> np.concatenate((a, b.T), axis=1)
array([[1, 2, 5],
[3, 4, 6]])
np.vstack()&np.hstack()
np.vstack(tup)使用 沿着竖直方向将矩阵堆叠起来。 Note: the arrays must have the same shape along all but the first axis. 除开第一维外,被堆叠的矩阵各维度要一致。 示例代码:
import numpy as np arr1 = np.array([1, 2, 3]) arr2 = np.array([4, 5, 6]) res = np.vstack((arr1, arr2)) #array([[1, 2, 3], # [4, 5, 6]])np.hstack(tup) 沿着水平方向将数组堆叠起来。 Note: tup : sequence of ndarrays All arrays must have the same shape along all but the second axis. 示例代码:
import numpy as np arr1 = np.array([1, 2, 3]) arr2 = np.array([4, 5, 6]) res = np.hstack((arr1, arr2)) print res #[1 2 3 4 5 6] arr1 = np.array([[1, 2], [3, 4], [5, 6]]) arr2 = np.array([[7, 8], [9, 0], [0, 1]]) res = np.hstack((arr1, arr2)) print res #[[1 2 7 8] # [3 4 9 0] # [5 6 0 1]]问题 1
请注意距离矩阵中的结构化图案,其中某些行或列的可见亮度更高。(请注意,使用默认的配色方案,黑色表示低距离,而白色表示高距离。)
- 数据中导致行亮度更高的原因是什么?
- 那列方向的是什么原因呢?
答:数据中导致行亮度更高的原因可能是某测试样本为离群点,与训练样本的距离都较远。列方向的原因是某训练样本与大多测试样本的共性较低,不太有与其相似的测试样本.
Pandas
输入/输出
- 输入
df = pd.read_csv("./test.txt",sep=' ',header=None,names=['a','b','c','d','e']) #默认分隔符是逗号
| 参数 | 释义 |
|---|---|
| header | 指定第几行作为列名(忽略注解行),如果没有指定列名,默认header=0; 如果指定了列名header=None |
| names | 指定列名,如果文件中不包含header的行,应该显性表示header=None ,header可以是一个整数的列表,如[0,1,3]。未指定的中间行将被删除(例如,跳过此示例中的2行) |
- 输出
#csv文件 index是否要索引,header是否要列名,True就是需要
outputpath='d:/Users/chen_lib/Desktop/fenci.csv'
df.to_csv(outputpath,sep=',',index=False,header=False)
#xlsx文件
outputpath='d:/Users/chen_lib/Desktop/fenci.xlsx'
df.to_excel(outputpath,sep='\t',index=False,header=False)
#txt文件
df.to_csv('d:/Users/chen_lib/Desktop/fenci_result.txt',sep='\t',index=False)
修改列名
Dataframe
创建空DataFrame并添加行数据
# 创建空DataFrame
df = pd.DataFrame(columns = ['YJML','EJML','SJML','WZLB','GGXHPZ','CGMS'])
# 插入数据(忽略索引)
df = df.append(kjcgml.loc[i].append(bzwzcgml.loc[j]), ignore_index=True)
# 按索引添加
df.loc[i] = kjcgml.loc[i].append(bzwzcgml.loc[j])
遍历
df = pd.DataFrame(...)
for index, row in df.iterrows():
print row['c1'], row['c2']
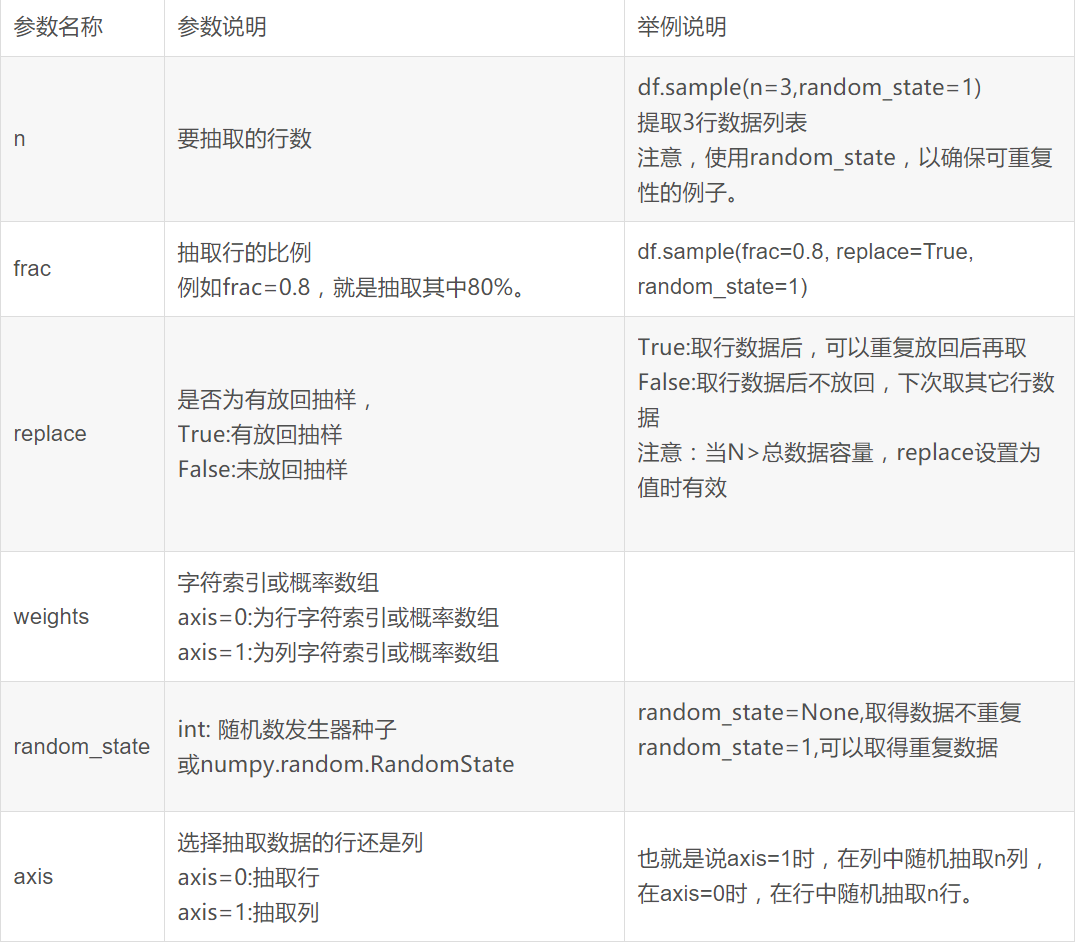
随机抽样
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)[source]
列操作
- 新建列
def one_hot(l,t):
if t in l:
return 1
else:
return 0
for t in types:
df[t] = df.apply(lambda x: one_hot(x['genres'],t) ,axis = 1)
- 对某列进行变化操作
movie_info['genres'] = movie_info['genres'].map(lambda x : x.split('|'))
- 删除列
方法一:直接del DF['column-name']
方法二:采用drop方法,有下面三种等价的表达式:
1. DF= DF.drop('column_name', 1);
2. DF.drop('column_name',axis=1, inplace=True)
3. DF.drop([DF.columns[[0,1, 3]]], axis=1,inplace=True) # Note: zero indexed
行操作
删除重复行
data.drop_duplicates(subset=['A','B'],keep='first',inplace=True) #subset对应的值是列名,表示只考虑这两列,将这两列对应值相同的行进行去重。默认值为subset=None表示考虑所有列。 #keep='first'表示保留第一次出现的重复行,是默认值。keep另外两个取值为"last"和False,分别表示保留最后一次出现的重复行和去除所有重复行。 #inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示生成一个副本。 data = data.reset_index(drop=True)
合并
横向
纵向
#concat_1.csv concat_2.csv # A,B,C,D A,B,C,D # a0,b0,c0,d0 a4,b4,c4,d4 # a1,b1,c1,d1 a5,b5,c5,d5 # a2,b2,c2,d2 a6,b6,c6,d6 # a3,b3,c3,d3 a7,b7,c7,d7 s1 = read_csv("concat_1.csv") s2 = read_csv("concat_2.csv") # s3 = read_csv("concat_3.csv") result = pd.concat([s1,s2,s3],sort=True).reset_index(drop=True) print(result)
Seaborn
pairplot:变量两两关系
https://zhuanlan.zhihu.com/p/98729226
pairplot主要展现的是变量两两之间的关系(线性或非线性,有无较为明显的相关关系)
- 对角线上是各个属性的直方图(分布图),而非对角线上是两个不同属性之间的相关图
引发异常
def ThorwErr():
raise Exception("抛出一个异常")
# Exception: 抛出一个异常
ThorwErr()
raise关键字后面是抛出是一个通用的异常类型(Exception),一般来说抛出的异常越详细越好,Python在exceptions模块内建了很多的异常类型,通过使用dir函数来查看exceptions中的异常类型,如下:
import exceptions
# ['ArithmeticError', 'AssertionError'.....]
print dir(exceptions)
Collection
Counter计数函数
https://blog.51cto.com/11026142/1851791
>>> c = Counter() # 创建一个新的空counter
>>> c = Counter('abcasdf') # 一个迭代对象生成的counter
>>> c = Counter({'red': 4, 'yello': 2}) # 一个映射生成的counter
>>> c = Counter(cats=2, dogs=5) # 关键字参数生成的counter
# counter 生成counter, 虽然这里并没有什么用
>>> from collections import Counter
>>> c = Counter('abcasd')
>>> c
Counter({'a': 2, 'c': 1, 'b': 1, 's': 1, 'd': 1})
>>> c2 = Counter(c)
>>> c2
Counter({'a': 2, 'c': 1, 'b': 1, 's': 1, 'd': 1})
因为 Counter 实现了字典的 __missing__ 方法, 所以当访问不存在的key的时候,返回值为0:
>>> c = Counter(['apple', 'pear'])
>>> c['orange']
0
counter 常用的方法:
# elements() 按照counter的计数,重复返回元素
>>> c = Counter(a=4, b=2, c=0, d=-2)
>>> list(c.elements())
['a', 'a', 'a', 'a', 'b', 'b']
# most_common(n) 按照counter的计数,按照降序,返回前n项组成的list; n忽略时返回全部
>>> Counter('abracadabra').most_common(3)
[('a', 5), ('r', 2), ('b', 2)]
# subtract([iterable-or-mapping]) counter按照相应的元素,计数相减
>>> c = Counter(a=4, b=2, c=0, d=-2)
>>> d = Counter(a=1, b=2, c=3, d=4)
>>> c.subtract(d)
>>> c
Counter({'a': 3, 'b': 0, 'c': -3, 'd': -6})
# update([iterable-or-mapping]) 不同于字典的update方法,这里更新counter时,相同的key的value值相加而不是覆盖
# 实例化 Counter 时, 实际也是调用这个方法
# Counter 间的数学集合操作
>>> c = Counter(a=3, b=1, c=5)
>>> d = Counter(a=1, b=2, d=4)
>>> c + d # counter相加, 相同的key的value相加
Counter({'c': 5, 'a': 4, 'd': 4, 'b': 3})
>>> c - d # counter相减, 相同的key的value相减,只保留正值得value
Counter({'c': 5, 'a': 2})
>>> c & d # 交集: 取两者都有的key,value取小的那一个
Counter({'a': 1, 'b': 1})
>>> c | d # 并集: 汇聚所有的key, key相同的情况下,取大的value
Counter({'c': 5, 'd': 4, 'a': 3, 'b': 2})
常见做法:
sum(c.values()) # 继承自字典的.values()方法返回values的列表,再求和
c.clear() # 继承自字典的.clear()方法,清空counter
list(c) # 返回key组成的list
set(c) # 返回key组成的set
dict(c) # 转化成字典
c.items() # 转化成(元素,计数值)组成的列表
Counter(dict(list_of_pairs)) # 从(元素,计数值)组成的列表转化成Counter
c.most_common()[:-n-1:-1] # 最小n个计数的(元素,计数值)组成的列表
c += Counter() # 利用counter的相加来去除负值和0的值